메모리 수요를 줄이는 기술이 메모리 주식을 떨어뜨렸어요.
터보퀀트, 구글의 알고리즘 하나가 메모리 주식을 흔들었다. 구글의 알고리즘 하나가 메모리 주식을 흔들었다 — 그런데 정말 흔들린 건 뭘까요? 수요일, 나스닥 100이 오르는 와중에 메모리 반도체 주식만 역행해서 빠졌어요. 샌디스크 -5.7
들어가며
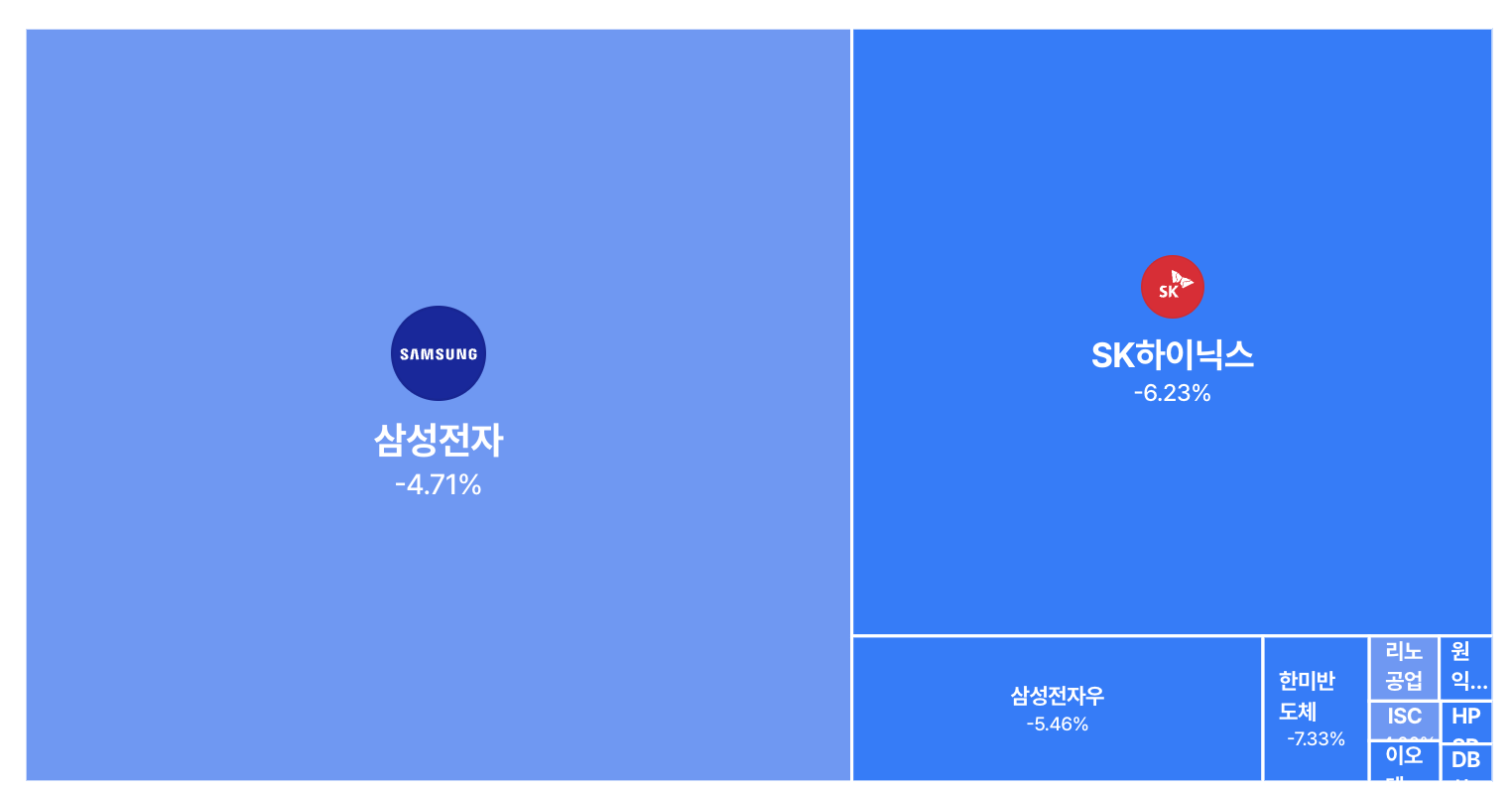
구독자님, 수요일 미국 증시에서 흥미로운 장면이 나왔어요. 나스닥 100이 상승하는 와중에, 메모리 반도체 주식만 역행해서 빠졌거든요. 샌디스크 -5.7%, 웨스턴 디지털 -4.7%, 씨게이트 -4%, 마이크론 -3%. 방아쇠를 당긴 건 구글 리서치가 공개한 터보퀀트(TurboQuant)라는 압축 알고리즘이었어요. 한국 주식시장에도 영향이 바로 있었어요. 현재 이 뉴스레터를 쓰고 있는 18시 기준으로, 삼성전자/하이닉스/한미반도체/리노공업/원익IPS 등 반도체 관련 기업들은 대부분 하락을 기록했어요.
“AI가 메모리를 덜 쓰게 해주는 기술” — 헤드라인만 보면 메모리 업체들에게 나쁜 소식처럼 보이죠. 그런데 이 기술이 실제로 줄이는 건 GPU 위의 임시 기억 공간(KV 캐시)이지, 서버에 꽂히는 HBM1이나 DRAM 모듈이 아니에요. 시장이 읽은 신호와 기술이 말하는 신호 사이에 간극이 있고, 그 간극 너머에는 AI 하드웨어 전체에 걸친 더 큰 질문이 있어요. 오늘은 그 간극과 질문을 함께 짚어볼게요. (솔직히, 원리 별로 안궁금하면 “시장은 왜 반응했을까”파트로 바로 넘어가세요!”)
터보퀀트가 실제로 하는 일
먼저 기술부터 정리해볼게요. AI가 대화를 이어갈 때, 앞에서 한 말을 기억하려면 KV 캐시2라는 임시 메모리에 정보를 저장해야 해요. 대화가 길어질수록 이 메모리는 기하급수적으로 늘어나고, 이게 AI 서비스 비용을 올리는 주범 중 하나예요. 터보퀀트는 이 기억을 최대한 작게 압축하면서도, 내용을 거의 그대로 유지하는 알고리즘이에요. 추가 학습이나 파인튜닝이 필요 없고요.
핵심 아이디어를 비유로 설명하면 이래요. 원래 AI가 저장하는 데이터는 숫자의 크기가 제각각이에요. 어떤 값은 크고, 어떤 값은 작고, 분포가 들쭉날쭉하죠. 이런 데이터는 효율적으로 압축하기 어려워요. 터보퀀트의 첫 번째 단계인 폴라퀀트(PolarQuant)는 이 데이터에 무작위 회전(random rotation)을 적용해서, 모든 값들의 분포를 균일하게 만들어 버려요. 마치 크기가 제각각인 짐들을 한번 잘 뒤섞어서 전부 비슷한 크기로 정리하는 거예요. 이렇게 되면 동일한 규격의 상자에 아주 효율적으로 담을 수 있어요. 논문의 수학적 표현으로는, 회전 후 각 좌표가 베타 분포를 따르게 되면서 좌표 간 거의 독립적이 되어 최적의 스칼라 양자화3를 개별 적용할 수 있다는 거예요.

그런데 여기서 한 가지 문제가 더 있어요. AI는 단순히 정보를 저장하는 게 아니라, 저장된 정보들끼리 얼마나 비슷한지 비교(내적 연산)하는 작업을 끊임없이 해요. 논문이 증명한 바에 따르면, MSE(평균제곱오차)에 최적화된 양자화기는 이 비교값에서 체계적 편향(bias)이 생겨요. 그래서 두 번째 단계인 QJL(양자화된 존슨-린덴스트라우스)이 필요해요. 1차 압축으로 덩어리를 줄인 뒤, 남은 잔여 오차(residual)를 단 1비트로 한 번 더 보정하는 방식이에요. 이 2단계 접근법 덕분에 비교값의 편향이 완전히 제거돼요.
논문의 실험 결과를 보면, 3.5비트에서 원래 모델과 사실상 동일한 품질을 유지하고, 2.5비트로 더 과감하게 줄여도 품질 저하가 미미했어요. Llama-3.1-8B-Instruct 모델 기준으로 LongBench 벤치마크 평균 점수가 비압축 대비 거의 같았고(50.06 vs 50.06), 10만 4천 토큰 길이의 Needle in a Haystack 테스트에서는 100% 정확도를 유지했어요. 압축률은 4.5배 이상이고요.
특히 인상적인 건 속도예요. 기존 제품 양자화(PQ) 방식이 1,536차원 데이터를 인덱싱하는 데 약 240초가 걸렸는데, 터보퀀트는 0.0013초밖에 안 걸렸어요. 약 18만 배 차이예요. 이건 터보퀀트가 데이터에 맞춰 코드북을 학습할 필요가 없는 온라인(data-oblivious) 방식이기 때문이에요.
다만 한 가지 짚어야 할 게 있어요. 구글 블로그에서 강조한 “최대 8배 속도 향상”이라는 숫자는 어텐션 로짓 연산이라는 특정 단계에서, JAX 베이스라인 대비로 측정된 거예요. 전체 추론 처리량(end-to-end throughput)의 8배가 아니에요. 그리고 “6배 메모리 축소”도 블로그와 논문 사이에 미세한 차이가 있어요 — 논문은 좀 더 보수적으로 “4.5배 이상”이라고 표현해요. 수치가 발표 채널에 따라 다르게 포장되는 건, 기술 뉴스를 읽을 때 늘 주의해야 할 부분이에요.
시장은 왜 반응했을까
시장의 논리는 단순해요. “AI가 메모리를 6분의 1만 써도 된다면, 메모리 수요가 줄어드는 거 아닌가?” 올해 메모리 주식들이 워낙 많이 올랐기 때문에(샌디스크는 연초 대비 200% 이상 상승), 차익 실현의 구실이 필요했던 측면도 있어요. 하지만 여기서 한 발짝 뒤로 물러나서 보면, KV 캐시와 HBM은 같은 “메모리”라는 단어를 쓰지만 작동하는 층위가 다르다는 점을 알 수 있어요.
KV 캐시는 LLM이 대화를 이어갈 때, 이전에 계산한 어텐션 데이터를 다시 계산하지 않으려고 GPU 메모리에 임시로 저장하는 것이에요. 컨텍스트 윈도가 100만 토큰으로 늘어나면, Llama 3 70B 모델 기준으로 KV 캐시만 약 512GB를 잡아먹어요. 모델 가중치 자체보다 4배나 큰 용량이에요. 그래서 KV 캐시 압축은 지금 AI 인프라에서 가장 뜨거운 연구 주제 중 하나예요.
반면 HBM 수요는 모델의 훈련과 추론 전체에 걸친 대역폭 병목에서 나와요. TrendForce 추정에 따르면 2026년 HBM 수요는 전년 대비 70% 증가할 전망이고, 뱅크오브아메리카는 2026년 HBM 시장 규모를 약 546억 달러(전년 대비 58% 증가)로 예측하고 있어요. SK하이닉스, 삼성, 마이크론 모두 2026년 HBM 생산 물량이 사실상 완판(sold out) 상태라고 밝히고 있고요.
쉽게 비유하면 이래요. 터보퀀트는 사무실 책상 위의 메모 정리법을 개선한 것이고, HBM 수요는 건물 자체에 더 많은 사무실이 필요한 것이에요. 메모를 효율적으로 정리한다고 건물 수요가 줄어들지는 않아요. 오히려 메모 정리가 잘 되면 한 사무실에서 더 많은 일을 처리할 수 있으니까, 건물을 더 짓고 싶어질 수도 있죠.
구글만의 이야기가 아니에요 — 엔비디아의 KVTC
여기서 놓치기 쉬운 맥락이 하나 더 있어요. KV 캐시 압축은 구글만 하는 게 아니에요. 같은 ICLR 2026 학회에서 엔비디아도 KVTC(KV Cache Transform Coding)라는 기술을 발표해요. JPEG 이미지 압축에서 쓰는 변환 코딩 원리를 KV 캐시에 적용한 건데, 최대 20배 압축을 달성했다고 주장하고 있어요. 특정 케이스에서는 40배까지도 가능하다고요. (젠장, 또 너야?)
구글의 터보퀀트(6배 압축, 학습 불필요)와 엔비디아의 KVTC(20배 압축, 사전 보정 필요)는 접근 방식이 다르지만, 해결하려는 문제는 같아요. 그리고 엔비디아는 KVTC를 자사의 추론 프레임워크인 Dynamo에 통합할 계획이에요.
이게 왜 중요하냐면, KV 캐시 압축 기술이 실전 배치되면 같은 GPU로 더 긴 컨텍스트, 더 많은 동시 요청을 처리할 수 있게 돼요. AI 사업자 입장에서는 추론 비용이 줄어드는 거죠. 효율이 올라가면 수요가 줄까요? 꼭 그렇지만은 않아요 — 이전 뉴스레터에서 다뤘던 제번스 패러독스4를 떠올리시면 돼요. 하지만 시장은 좀 다른 각도에서 이 기술을 읽고 있어요.
오스왈드의 시선
저는 터보퀀트 자체보다, 이 뉴스에 시장이 반응한 방식이 더 흥미로워요. 왜냐하면 이건 메모리 주식만의 이야기가 아니거든요.
좀 더 넓게 보면, 지금 AI 하드웨어 스택 전체가 같은 질문을 받고 있어요. 엔비디아는 2026 회계연도에 매출 2,159억 달러, 순이익률 55% 이상이라는 전례 없는 실적을 기록했는데, 주가는 작년 10월 고점 대비 약 11% 낮은 수준에서 움직이고 있어요. 마이크론도 마찬가지예요. 이틀 전 역대 최고 분기 실적(매출 238.6억 달러, 매출총이익률 74.9%)을 발표했지만, 시장의 반응은 “250억 달러 이상의 설비투자를 감당할 수 있느냐”에 쏠렸죠. GPU도 떨어지고, DRAM도 떨어지고, NAND 스토리지도 떨어지고 있어요.
시장이 묻고 있는 진짜 질문은 “이 속도의 인프라 투자가 지속 가능한가”예요. 빅테크 4사(마이크로소프트, 메타, 알파벳, 아마존)의 2026년 설비투자 가이던스 합산이 6,500~7,000억 달러에 달해요. 이건 인류 역사에서 단일 목적에 투입된 민간 자본 중 가장 큰 규모에 속해요. 투자자들 사이에서는 “이 투자의 수익률이 정당화될 수 있느냐”는 논쟁이 점점 커지고 있고요. 우리가 흔히 “AI 버블”이라고 했던 것도 이러한 맥락 속에서 나왔던 이야기이구요.
GTM 전략 관점으로 제가 보는 프레임은 이래요. 모든 기술 인프라 사이클에는 “건설 국면”과 “최적화 국면”이 있어요. 건설 국면에서는 “일단 깔아라”가 전략이에요. 최적화 국면에서는 “깔아놓은 것의 효율을 어떻게 극대화할 것인가”가 전략이 돼요. 터보퀀트, 엔비디아의 KVTC, 그리고 하이퍼스케일러들의 자체 칩(구글 TPU, 아마존 Trainium) 개발 — 이 모든 움직임은 최적화 국면의 신호예요.
그렇다고 이게 약세 신호냐? 저는 아니라고 봐요. 최적화 국면은 성장의 끝이 아니라 성장이 성숙해지는 과정이에요. 다만 시장이 가격에 반영하는 방식이 달라질 뿐이에요. 건설 국면에서는 “다 사”였다면, 최적화 국면에서는 누가 이 효율화의 수혜자이고 누가 비용을 부담하는가를 가려야 해요.
지금 메모리 시장의 펀더멘털은 여전히 강해요. HBM 물량은 2026년 내내 완판이고, BofA 추정 시장 규모는 546억 달러(전년 대비 58% 성장)예요. 하지만 “알고리즘이 하드웨어를 대체한다”는 내러티브가 한 번 투자자의 머릿속에 들어가면, 밸류에이션이 높을수록 민감하게 반응할 수밖에 없어요. 샌디스크가 연초 대비 200% 넘게 올랐다면, 논문 한 편이 -5.7%를 만들 수 있는 거죠.
핵심은 시간 축의 구분이에요. 터보퀀트 같은 소프트웨어 최적화가 하드웨어 수요의 증가 속도에 영향을 줄 수 있는 건 2027년 이후의 이야기예요. 2026년의 메모리 공급 부족은 물리적인 팹 건설과 수율의 문제이고, 알고리즘으로 해결되는 영역이 아니에요. 시장이 이 두 가지 시간 축을 혼동할 때, 그게 바로 기회이기도 하고 리스크이기도 해요.
마치며
한 가지 더 짚고 마무리할게요.터보퀀트의 원본 논문(arXiv:2504.19874)이 게재된 날짜는 2025년 4월 28일이에요. 거의 1년 전이죠. 누군가는 이 기술을 1년 동안 계속 벼려내고, 구글 리서치 블로그에 올리고, ICLR 2026 발표를 준비하고, 마침내 시장을 흔들었어요. 연구실에서 나온 아이디어가 월스트리트의 주가를 움직이기까지, 그 사이의 시간 동안 무엇이 쌓였는지를 생각해보면 흥미로워요.
정리하면 이래요. 터보퀀트는 AI 추론 효율을 한 단계 끌어올리는 의미 있는 기술이에요. 하지만 오늘 메모리 주식이 빠진 이유는 이 기술 하나가 아니라, AI 하드웨어 스택 전반에 걸친 “건설에서 최적화로”의 국면 전환 신호를 시장이 읽기 시작했기 때문이에요. 기술의 층위를 이해하고 시간 축을 구분할 수 있다면, 이런 변동성 속에서 더 나은 판단을 내릴 수 있어요.
1년 전의 논문이 오늘의 시장을 흔들었다면, 지금 연구실에서 나오고 있는 논문들은 1년 뒤에 무엇을 흔들게 될까요?
⚠️ 이 뉴스레터는 특정 종목에 대한 투자 권유가 아니에요. 투자 판단은 반드시 본인의 분석과 전문가 상담을 거쳐 내려주세요.
참고자료 & 더 읽기
- Zandieh, A., Daliri, M., Hadian, M., & Mirrokni, V., “TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate”, arXiv:2504.19874, 2025. ICLR 2026 발표 예정. : 오늘 뉴스레터의 핵심인 터보퀀트 논문 원문이에요. 2단계 압축 구조의 수학적 증명과 실험 결과를 직접 확인할 수 있어요. 특히 Table 1(LongBench 결과)과 Figure 4(Needle in a Haystack 결과)가 핵심이에요.
- Google Research, “TurboQuant: Redefining AI efficiency with extreme compression”, 2026. : 논문을 일반 독자용으로 정리한 구글 리서치 블로그예요. 다만 블로그와 논문 사이에 수치 표현의 미세한 차이가 있으니, 정확한 수치는 논문을 참고하세요.
- Łańcucki et al., “KV Cache Transform Coding for Compact Storage in LLM Inference”, ICLR 2026. : 엔비디아의 KVTC 논문이에요. 터보퀀트와 접근법이 어떻게 다른지 비교해보면 KV 캐시 압축의 전체 지형이 보여요.
- Investing.com, “MU, WDC, SNDK fall: Why Google’s TurboQuant is rattling memory stocks”, 2026.3.25. : 오늘의 메모리 주식 하락을 다룬 기사예요.
- SK hynix, “2026 Market Outlook: SK hynix’s HBM to Fuel AI Memory Boom”, 2026.1. : 2026년 메모리 시장의 구조적 수요를 이해하는 데 도움이 돼요. HBM3E와 HBM4의 수요 전망이 정리되어 있어요.
- Fortune, “Rampant AI demand for memory is fueling a growing chip crisis”, 2026.2. : AI가 메모리 시장 전체를 어떻게 재편하고 있는지를 보여주는 심층 기사예요.
- CNBC, “Even a $1 trillion forecast can’t break Nvidia out of a 2026 funk”, 2026.3. : 엔비디아의 역대급 실적에도 주가가 횡보하는 이유를 분석한 기사예요. “건설→최적화 국면 전환”의 시장 심리를 이해하는 데 좋아요.
- VentureBeat, “Nvidia says it can shrink LLM memory 20x without changing model weights”, 2026.3. : 엔비디아의 KVTC 기술을 실무 배치 관점에서 다룬 기사예요. 구글 터보퀀트와의 차이를 이해하는 데 좋은 보완 자료예요.

필자 안광섭은 세종대학교 경영학과 교수이자 OBF(Oswarld Boutique Consulting Firm) 리드 컨설턴트이다. 대학에서 경영데이터 관리, 비즈니스 애널리틱스 등 통계 및 데이터 분석을 가르치는 한편, 현장에서는 GTM 전략과 인공지능 전략 컨설팅을 이끌며 기술과 비즈니스의 접점을 설계하고 있다. AI 대화 시스템의 기억 아키텍처(HEMA) 연구로 학술 논문을 발표했으며, 매일 글로벌 AI 논문을 큐레이션하는 Daily Arxiv 프로젝트를 운영하고 있다. 고려대학교 기술경영전문대 석사과정와 KMBA을 졸업했다. 지은 책으로 《생각을 맡기는 사람들: 호모 브레인리스》가 있다.
각주
-
HBM (High Bandwidth Memory): AI 칩(GPU) 바로 옆에 수직으로 쌓아 올린 초고속 메모리예요. 일반 DRAM보다 데이터 전송 속도가 몇 배나 빠르기 때문에, AI 훈련과 추론에서 핵심 부품으로 자리 잡았어요. ↩
-
KV 캐시 (Key-Value Cache): LLM이 대화할 때, 이전에 계산한 “핵심 정보(Key)“와 “값(Value)“을 저장해두는 임시 메모리예요. 이걸 저장하지 않으면 매번 처음부터 다시 계산해야 해서, 대화가 길어질수록 이 캐시가 GPU 메모리를 크게 차지해요. ↩
-
양자화 (Quantization): 정밀한 소수점 숫자(예: 32비트)를 더 적은 비트(예: 4비트, 3비트)로 줄이는 기술이에요. 파일 용량은 줄어들지만, 너무 과하게 줄이면 정보가 뭉개질 수 있어요. ↩
-
제번스 패러독스 (Jevons Paradox): 자원의 사용 효율이 좋아지면 오히려 총 사용량이 늘어나는 현상이에요. 19세기 영국 경제학자 윌리엄 스탠리 제번스가 석탄 효율 향상이 석탄 소비 감소로 이어지지 않았다는 관찰에서 유래했어요. ↩