China Bets on Efficiency, Japan on Command, Korea: ₩800T
Seoul's new megaprojects buy AI's body—chips, robots, data centers—while the intelligence meant to run it is left unclaimed.
Opening
Dear reader, over the last two newsletters I put the same question to two different countries.
In the Japan issue (The Researcher Who Left with ₩900 Billion (~$650M), and the 138 Who Stayed in Tokyo), I asked: “Is AI a game of capital, or a game of methodology?” Sakana AI used a small 7B orchestrator to conduct frontier models and squeeze out frontier-grade performance. It was the first working proof of the hypothesis that “you can win without building bigger.”
The lab that chose kaizen over the compute war
In the Korea issue (The Country That Asks Chatbots for Its Fortune — What Would It Take to Rank No. 3 in AI?), I asked: “Will Korea be a country that builds AI, or the country that uses it best?” Korea’s enthusiasm ranks No. 1 in the world, yet the model gap sits at 40%, talent is draining away at 35th place in the OECD, and the insistence on building a “sovereign model” from scratch risks becoming Galapagos syndrome all over again.
World-leading enthusiasm, a 40% model gap
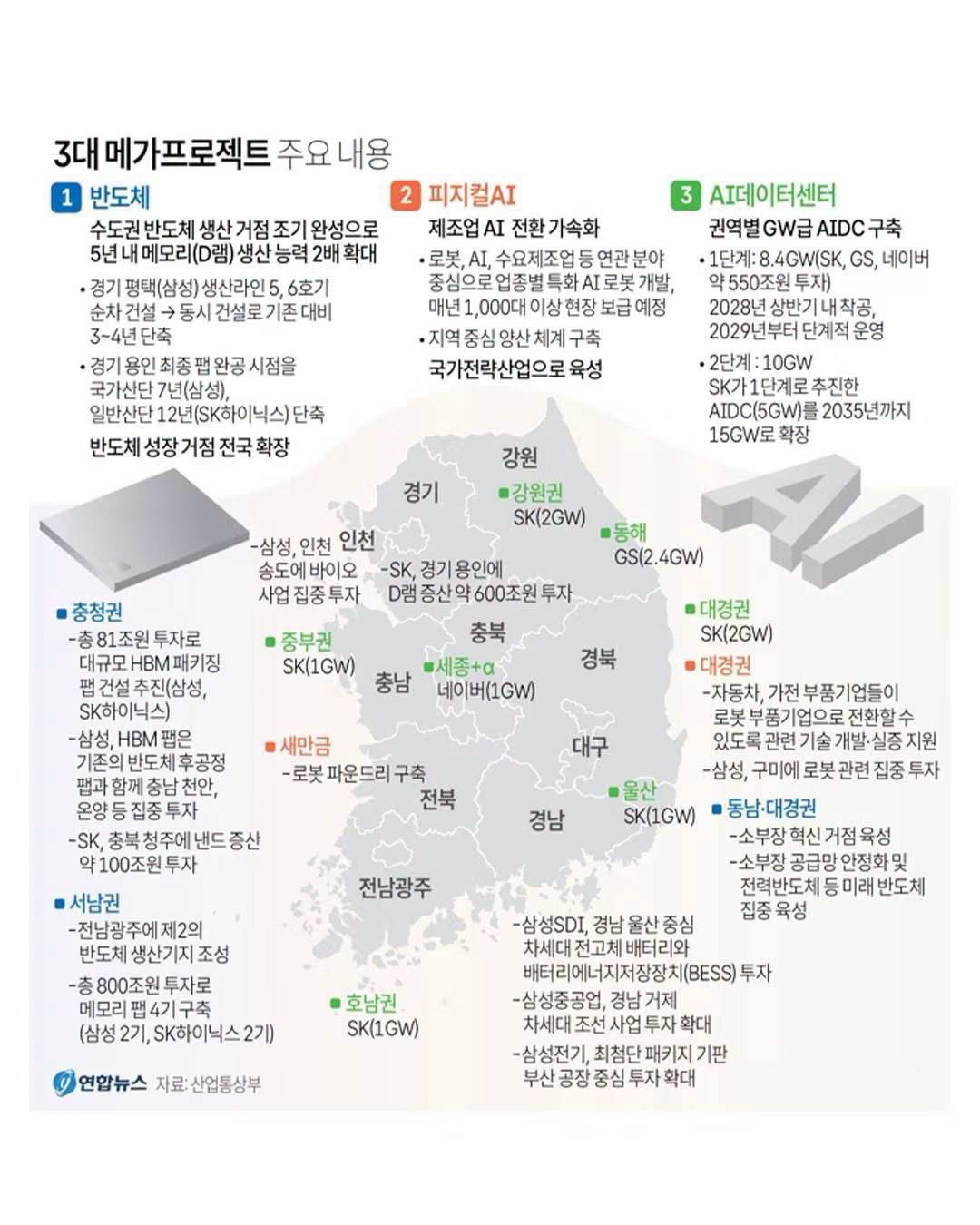
While writing those two issues, I deliberately set one thing aside. Korea’s hand — the cards it would bring to the game — had not yet been dealt. Then, on June 29, that hand was revealed at the Yeongbin-gwan state guest house of the Blue House. The Ministry of Trade and Industry, jointly with related ministries, held the “National Briefing on the Republic of Korea’s Great Leap: Three Mega-Projects.” ₩800 trillion (~$580 billion) for semiconductors, ₩550 trillion for AI data centers, and physical AI designated a national strategic industry. On the numbers alone, it is overwhelming.
So today concludes the 3-part series. I will lay out side by side which layer China, Japan, and Korea each bet on, and examine what is in the hand Korea revealed yesterday — and what is missing from it. To give you the conclusion up front: Korea’s bet is smarter than I expected, but the single most important square on the board is empty.
Same Game, Three Different Courts
First, let me summarize in one picture where the three countries have placed their money and talent. The key point is that they are fighting on different layers. They all get lumped under the same phrase, “the AI race,” but in practice they are competing in different events.
🇨🇳 China: Making Scaling Efficient
China is following American-style scaling, but under the constraint of sanctions it has redefined the game around “efficiency.” DeepSeek is the symbol. In late 2024, it pushed R1 to ChatGPT o1-class performance on just 2,048 H800s; in April 2026 it shook the board again with V4, bringing million-token context and sparse attention. In June it announced the DSpark framework, boosting response speed by up to 85% while reducing dependence on ever-larger chip infrastructure.1
What is fascinating is that even inside China, the center of gravity has already shifted from “training” to “inference,” from “building models” to “using models well.” Reports have emerged that of the roughly 500 data centers thrown up in the post-ChatGPT frenzy, as many as 80% sit idle.2 China is still scaling, but not the American way — it is carving down the cost curve itself. Qwen, GLM, and DeepSeek are rapidly driving up global adoption with open weights plus rock-bottom API pricing. In fact, Chinese models are so absurdly cost-effective that they are winning the affection of American companies, geopolitics notwithstanding.
Uber burned through its entire AI coding-tool budget for the year in just 4 months. With roughly 5,000 engineers using agentic coding tools, monthly costs rose from $150 per engineer to as much as…
🇯🇵 Japan: Orchestration
Japan stepped out of the race to build models directly. Sakana AI itself explicitly declared that “for a resource-constrained country like Japan, the focus of model development should be on post-training.”3 And on June 22, it proved that philosophy with a product: Sakana Fugu.
A small 7B-parameter orchestrator directs frontier models like GPT-5.5, Claude, and Gemini — deciding who handles which part, verifying the results, and recursively calling itself when needed. Fugu Ultra outperformed Opus 4.8, Gemini 3.1 Pro, and GPT-5.5 on major benchmarks including SWE-Pro, GPQA-D, and LiveCodeBench. Sharper still: Fable 5 and Mythos Preview, locked out by export controls, were not even in the agent pool — and Fugu matched their class of performance anyway.4
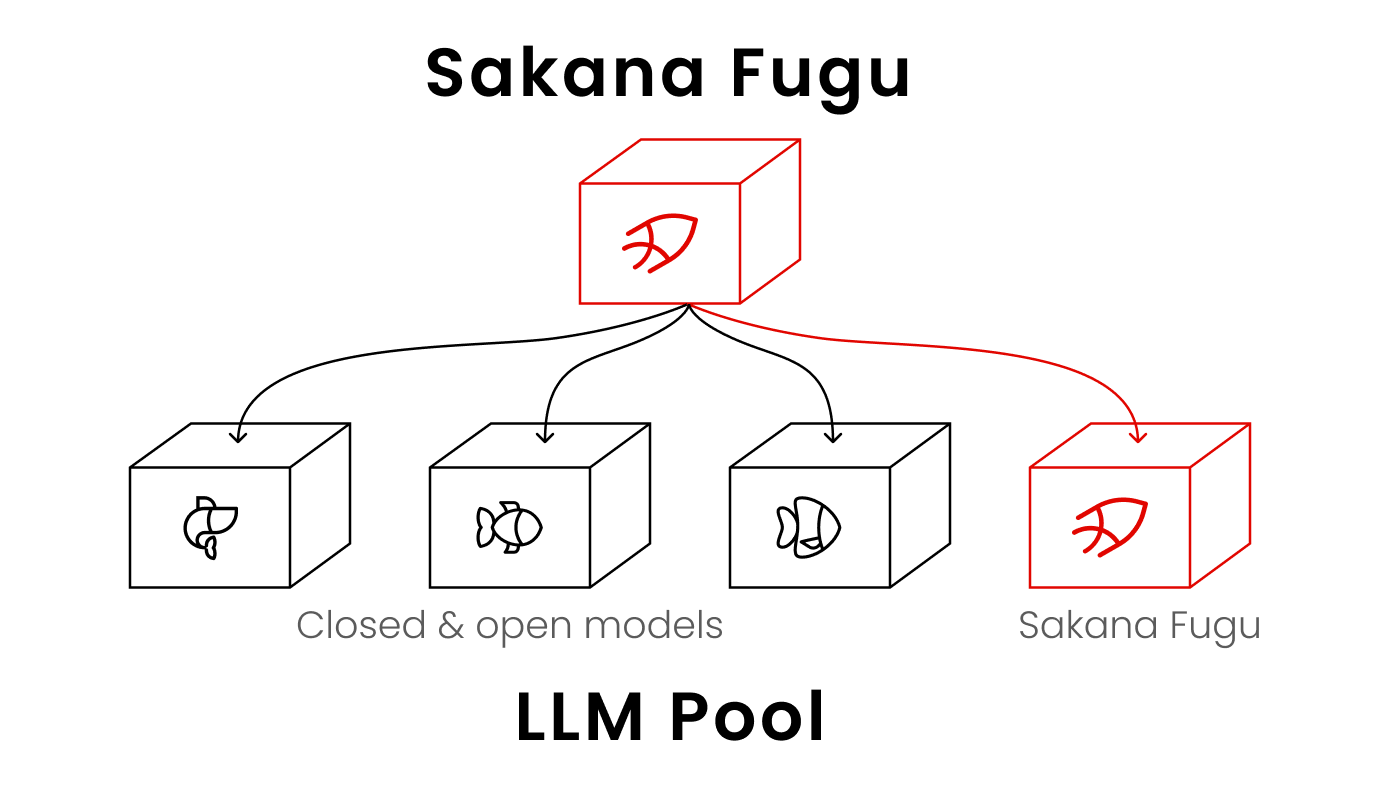
This is decisive from a Sovereign AI perspective. Even if a particular frontier model gets caught in export controls, Fugu dynamically recombines only the accessible models (the Swappable Pool) and reconstitutes equivalent performance. Just as fugu — the pufferfish — becomes a delicacy once its poison is precisely cut away, this is an architecture that protects AI sovereignty by routing around the poison of external regulation. It is a strategy of holding “command” over models without owning them.
🇰🇷 Korea: The Physical Layer
And yesterday, Korea showed its hand. The center of gravity is unmistakable: semiconductors, physical AI, AI data centers. Korea is betting not on AI’s “software” but on the “physical body and heart” that AI will ride on.
- Semiconductors: ₩800 trillion invested in the southwest region (South Jeolla and Gwangju), 4 memory fabs. Double DRAM production capacity within 5 years. The goal is to widen the supply-chain lead Korea already holds through HBM.
- Physical AI: top 3 globally in AI robotics, No. 1 globally in physical AI (~2030). Specialized humanoids for 10 key industries, AI transformation of manufacturing.
- AI data centers: Phase 1 at 8.4GW (SK, GS, Naver — roughly ₩550 trillion), 18.4GW total through Phase 2. The largest AI infrastructure hub in Asia-Pacific by 2030.
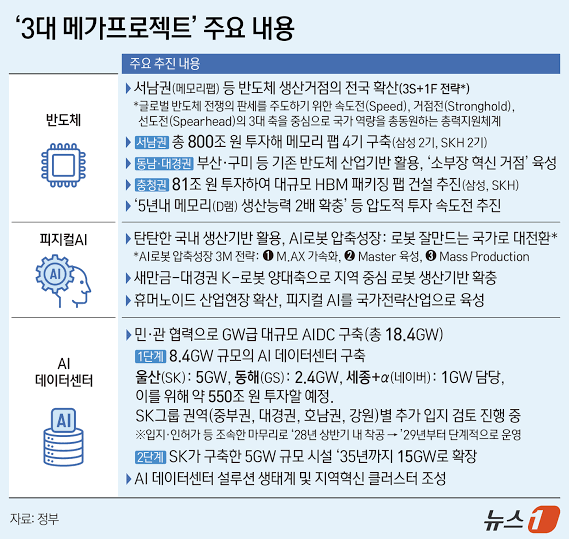
In the Korea issue I wrote that Korea should “fuse AI most deeply into the domains where it already has global competitiveness — semiconductor process optimization, battery quality control” — and yesterday’s M.AX and the manufacturing data factory point exactly in that direction. It is the national-scale version of the “country that uses AI best” strategy.
Korea’s Bet Is Half Right
Let me start with the praise. This bet is smarter than what I feared in the Korea issue.
Beating the US and China head-on in the foundation-model race is unrealistic. US private AI investment alone is $285.9 billion — 42 times Korea’s entire AI budget ($6.7 billion). Claiming you will close that gap on model performance is closer to self-rationalization. But yesterday’s announcement avoids that frontal assault and puts its weight on the domains where Korea is genuinely No. 1: HBM, manufacturing density, robot density.
In particular, physical AI is a clever choice. The game is completely different from the text-LLM race. Here, Korea’s manufacturing data, its process-operations know-how, and its world-leading density of 1,220 robots per 10,000 workers become real assets. It is a domain where American big tech has neither the data nor much interest, so the competitive landscape itself is different. The position — “rent the brain (the foundation model), but build the body and the heart ourselves” — is, frankly, a hundred times more realistic than “beat GPT with a sovereign foundation model.”
That is the good half. The problem is the other half.
But There Is No Conductor
Reading yesterday’s announcement again from start to finish, one thing kept nagging at me. There are semiconductors. There are robots. There are data centers. But the layer that answers “how will this intelligence be combined and commanded” is missing entirely.
Japan filled that square with Fugu. In Korea’s document, the square does not exist. What sits in its place instead: “a K-model that escapes dependence on foreign technology,” “securing a world-class general intelligence model,” “developing a world-class sovereign physical AI foundation model within 3 years.”
To see why this is a problem, I have to bring back the episode I covered in the Korea issue. In January this year, Naver Cloud was eliminated from the government’s sovereign AI foundation model (“Dokpamo”) project. The reason: it had used a foreign open-source encoder and therefore failed the “from scratch” criterion5. It was the moment that exposed the fact that even the company that had invested in AI the longest and the most in Korea did not have a model “built from scratch.”
That Dokpamo project is now a four-way race between LG, SKT, Upstage, and Motif Technologies; the Round 2 evaluation this August will cut 1 team, and the final 2 will be selected next February6. And yesterday’s megaproject cloned that “from-scratch Dokpamo” DNA straight into a physical AI edition. A game Korea could not win in general-purpose LLMs is being restarted with only the stage swapped — to physical AI foundation models.

This is where the decisive difference from Japan shows.
Japan has Sakana — a private frontier lab that actually made the methodology work — so it can layer a self-improvement engine and an orchestration layer on top of its consortium (AIST, Swallow, Stockmark). Without building every model itself, it holds the intelligence that commands models.
In Korea, that seat is empty. There is no clear owner of the orchestration layer, and no proven private physical-AI lab. Naver’s elimination revealed precisely that absence. The government intends to fill the void with a “pan-ministerial large-scale R&D project” — but whether a consortium-style national program can run a Sakana-style kaizen loop is an entirely different question. While the state pours ₩800 trillion into building the body, the conductor that moves that body is still, most likely, going to be a foreign frontier model.
That is the real gap in yesterday’s announcement. Before pouring ₩800 trillion into the physical layer, the architecture of the intelligence that will sit on top of it should have been decided first. A single line about Fugu-style orchestration — it is nowhere to be found.
Oswarld’s Take
Let me be blunt. The judgment to shift weight to the physical layer in yesterday’s announcement — that was right. And that is exactly as far as it goes. On top of that clever judgment, I saw the oldest disease of Korean AI policy laid on unchanged.
The disease is called the compulsion to build.
In technology management and GTM strategy work, there is a losing pattern I have seen countless times: the moment the resource-poor side insists, “we still have to build everything ourselves.” The phrases in yesterday’s document — “escape foreign dependence,” “world-class sovereign model,” “sovereign physical AI foundation model within 3 years” — are not strategy. They are pride. And pride carries a steep price. A game already proven lost by a 40% gap in general-purpose LLMs is being set up to be lost again, identically, with the stage merely switched to physical AI. The “from scratch” criterion that eliminated Naver in January has been resurrected — this time on top of robots.
What is more exasperating is that this is not for lack of seeing Japan. Right next door, Japan proved with a product that a single small 7B model can “win without building everything.” It chose to command models rather than own them. Korea has that answer sheet right under its nose and still clings to the old grammar of “we will build it all from scratch.” Instead of studying kaizen, it wants to build a bigger factory.
Look at the asymmetry coldly. China solved scaling with efficiency; Japan solved it with orchestration. Both have their own answer to “how do we handle intelligence.” And Korea? It has the body (semiconductors) and the heart (data centers), but not a single page of blueprints for the nervous system that would connect the two. In an ₩800 trillion anatomical chart, the brain and the spinal cord are blank. That space is filled by the slogan “sovereign model R&D” — which is not a blueprint, it is wishful thinking.
The scenario that truly frightens me is this: 5 years from now, Korea completes the most sophisticated AI body in the world. No. 1 in HBM, No. 1 in robot mass production, the largest data centers in Asia-Pacific. And the intelligence moving that entire body is GPT, or Gemini, or Fugu. The sentence I wrote in the Korea issue — “this is the realm of supplying parts, not of owning something of our own” — repeats in physical AI without a single word changed. A country that builds the world’s most expensive vessel and fills it with someone else’s borrowed brain.
I do not know who the final winner will be. Perhaps whoever holds the physical layer takes it all. But that scenario rests on exactly one premise: we must be able to orchestrate the intelligence that rides on the body. Without that condition, ₩800 trillion is not a decisive move — it could become the world’s most expensive subcontracting capex. I do believe Korea has seized a once-in-a-lifetime opportunity in semiconductors. And I concluded that this policy emerged precisely because Korea holds some of the world’s finest skilled labor, equipment, and infrastructure, while sitting at a strategic crossroads both in terms of natural-disaster safety and geopolitics.
In other words: might Korea’s ideal picture be to become the Petra of data centers and every power base? And shouldn’t we be preparing the model that can conduct it all, and the capability to properly build and operate that infrastructure? That — imperfect as it is — is the conclusion I have come to.
Closing
To sum up.
The question I kept asking across this 3-part series was ultimately one: “In the AI race, which layer is the one truly worth fighting on?” China answered with the efficiency of scaling; Japan answered with orchestration. And yesterday, Korea answered with the physical layer. I consider all three smart choices fitted to each country’s conditions. I had grown weary of the endless one-note chorus about foundation models, so this announcement was genuinely refreshing. My view: keep foundation models as basic fitness, but they should not be our main event. We cannot catch up to frontier grade overnight anyway. And while we are at it, the benchmark games need to stop too.
But Korea’s answer has one blank square. The plan to build an ₩800 trillion body is missing the architecture of the intelligence that will command that body. The layer Japan proved with a single 7B orchestrator — Korea is still trying to solve it with the old grammar of a “from-scratch sovereign model.” Lately I keep seeing domestic startups and a few companies claiming world No. 1 on their own benchmarks — and if true, that genuinely is remarkable — but when a project posts its paper on Arxiv and gets single-digit citations, draws no attention on Github, and still publicly claims to have beaten NVIDIA to become the world’s No. 1 world model… isn’t there a bit of a gap there? Of course, it could just be that clueless foreign media fail to recognize the technology sitting in little Korea in the East… as if. Let’s get a grip.
The next time you watch a Korean AI policy announcement, ask not about the investment figures (₩800 trillion, ₩550 trillion) but this question: “On top of this infrastructure, whose what is orchestrating the intelligence?” If that square stays unfilled, Korea could build the world’s most sophisticated AI body — and end up renting someone else’s brain to put inside it.
Just as Cyworld built a social network faster than anyone in the world and still missed the mobile transition, I hope Korea, having built the AI body faster than anyone, does not miss the intelligence that goes on top of it.
💬 What do you think, dear reader? Will the AI race ultimately be decided by the “body” (the physical layer), or by “command” (orchestration)? Share your thoughts in the comments.
References & Further Reading
Primary sources
- Ministry of Trade and Industry, “National Briefing on the Republic of Korea’s Great Leap: Three Mega-Projects,” press reference materials and annexed report, 2026.06.29. : The original text of yesterday’s announcement, laying out the semiconductor 3S+1F, physical AI 3M, and 18.4GW AIDC plans.
- Sakana AI, “Sakana Fugu: One Model to Command Them All”, 2026. : The product-level proof of Japan’s orchestration strategy — and a core source for the Japan issue.
- Ministry of Science and ICT, “Round 1 Evaluation Results of the Sovereign AI Foundation Model Project,” 2026.01.15. : The original text behind Naver Cloud’s elimination and the “from scratch” criterion controversy.
Background
- The New York Times, “The Real A.I. Race Isn’t America vs. China”, 2026. : The view that the real axis of the AI race is not US vs. China but “state power vs. private companies” — closely aligned with the problem this 3-part series has been probing.
- ZDNet Korea, “[Yumi’s Pick] LG, SKT, and Upstage Meet Jensen Huang — A Wild Card in Round 2 of the Sovereign AI Race?,” 2026.06.09. : Covers the four-way Dokpamo race and the August second-round evaluation schedule.
- South China Morning Post / IndexBox, “DeepSeek upgrades V4 with DSpark”, 2026.06. : The latest example of China’s “scaling efficiency” strategy.

The author, Kwangseob Ahn, is a professor of business administration at Sejong University and lead consultant at OBF (Oswarld Boutique Consulting Firm). He teaches statistics and data analysis — including business data management and business analytics — at the university, while in the field he leads GTM strategy and AI strategy consulting, designing the interface between technology and business. He has published academic research on memory architecture for AI dialogue systems (HEMA) and runs Daily Arxiv, a project curating global AI papers every day. He completed a master’s program at Korea University’s Graduate School of Management of Technology and its KMBA. He is the author of Homo Brainless: The People Who Outsource Their Thinking.
Footnotes
-
DSpark: The inference-acceleration framework DeepSeek introduced with V4. Instead of generating tokens one at a time, it produces them in small batches (semi-autoregressive generation) and dynamically adjusts the amount of verification, boosting response speed by up to 85%, according to the announcement. The core aim is reducing dependence on ever-larger chips. ↩
-
Idle data centers: According to reporting by MIT Technology Review and others, of the roughly 500 data centers China announced in 2023–2024, only a fraction actually came online — and even at operating sites, analyses found up to 80% of computing resources sitting unused. It is the result of demand shifting from training-centric to inference-centric. ↩
-
Post-training: Rather than pretraining a model from the ground up, this is the stage of layering additional training, alignment, and tool connections on top of an already-trained model. Sakana argued that resource-constrained countries should place their strategic focus on this layer. ↩
-
Swappable Pool: The bundle of frontier models Fugu orchestrates. Even if a particular model drops out due to export controls or the like, the pool dynamically recombines the remaining accessible models to maintain performance. The goal is frontier performance without vendor lock-in. ↩
-
From scratch: An approach in which no existing models or weights are reused — weights are initialized and the entire process, from data collection to architecture design to training, is carried out in-house. It is the criterion the government set for a “sovereign model,” and Naver was eliminated under it for borrowing a foreign encoder. ↩
-
Dokpamo four-way race: As of June 2026, four teams are competing — LG AI Research, SK Telecom, Upstage, and Motif Technologies. 1 team is eliminated in the August Round 2 evaluation, with the final 2 selected in February 2027. ↩